KPMG Internal Data Science Platform
In Short
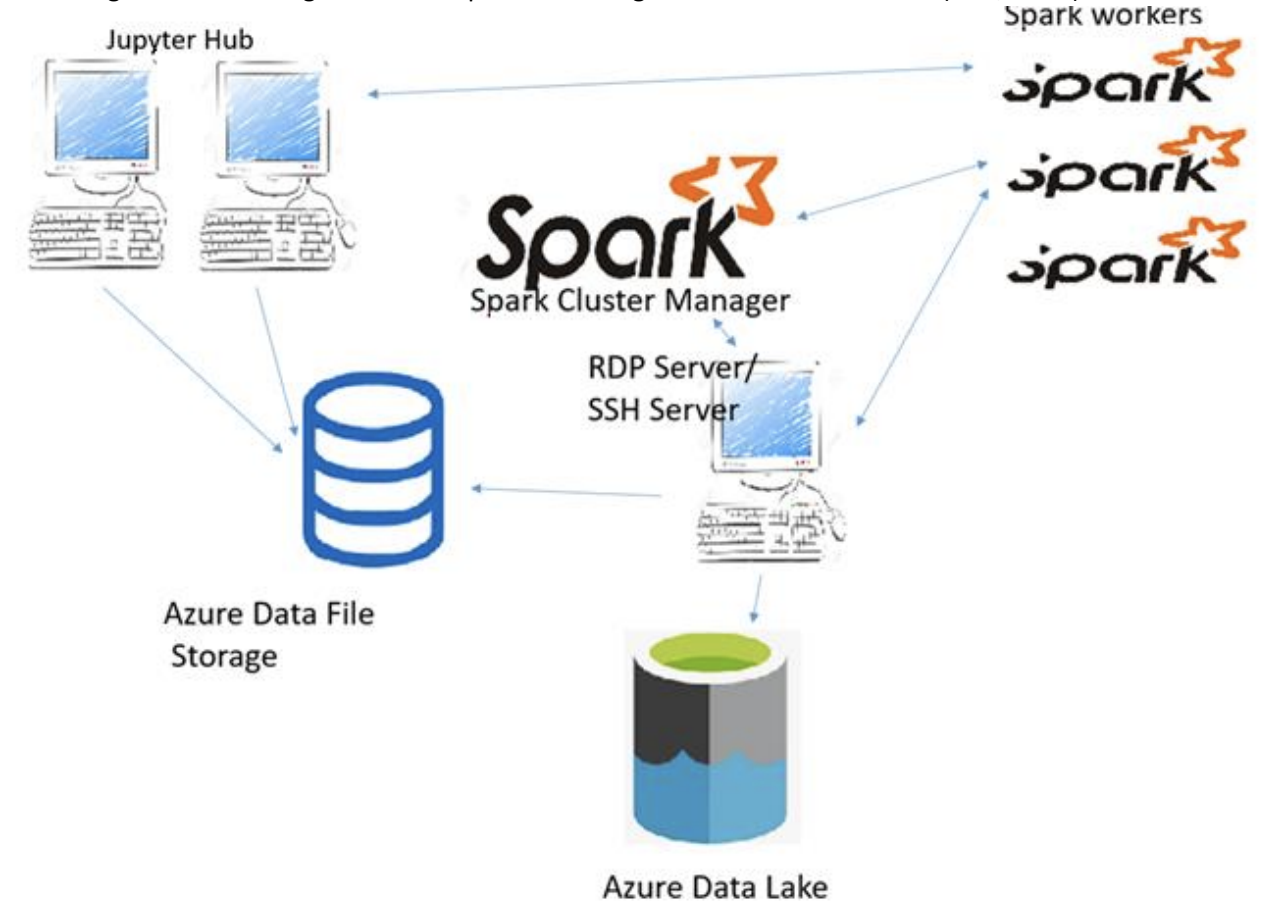
During an intership at KPMG, before I actually joined as a consultant, I was tasked to work on a Spark-based internal development platform to enable large scale Big Data Analytics, based on Spark, Hive, JupyterHub and Kubernetes.
Note that this was somewhat before platforms like DataBricks were widely used, and people had become accustomed by running their own Spark-clusters. There are not a whole lot of use-cases to go this way nowadays. Nonetheless, after a few months the product was replaced by the adoption of DataBricks.